信息系统运行维护服务 制度构建与高效运维实践

在现代企业的数字化运营中,信息系统的稳定、高效与安全运行已成为核心竞争力的关键支撑。一套科学、系统、规范的信息系统运行管理制度,是保障其持续可靠运行的基础,而专业的运行维护服务则是将制度落地、实现价值的核心环节。本文将从制度框架、运维实践与服务模式三个维度,探讨如何构建与优化信息系统的运行维护体系。
一、信息系统运行管理制度的构建
制度是行动的纲领。一个完善的信息系统运行管理制度体系,应覆盖从规划到退役的全生命周期,并聚焦于运行与维护阶段。其核心框架通常包括:
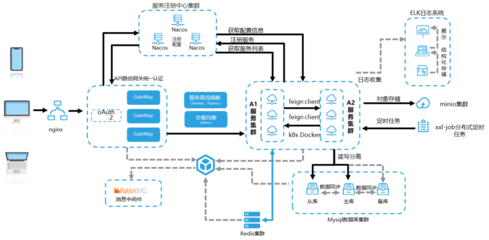
- 组织与职责制度: 明确信息系统运行维护的组织架构,定义决策层、管理层、执行层(如运维中心、服务台、技术支持团队)的权责边界。确立关键岗位,如系统管理员、网络工程师、安全审计员的职责与工作要求。
- 日常操作管理制度: 规范系统监控、日常巡检、备份与恢复、变更管理、事件管理、问题管理等例行工作流程。例如,规定监控指标的阈值、巡检的频率与内容、备份策略(全量/增量、本地/异地)、变更的审批与测试流程。
- 安全管理制度: 制定访问控制策略、密码管理规范、漏洞扫描与修补流程、安全事件应急响应预案、数据分类与保护要求等,以抵御内外部的安全威胁,保障信息资产的机密性、完整性与可用性。
- 资源与配置管理制度: 对硬件设备、软件许可、网络资源、机房环境等进行台账管理,建立配置管理数据库(CMDB),确保所有配置项的信息准确、可控,支撑高效的故障定位与影响分析。
- 服务级别与绩效管理制度: 定义各项运维服务的标准(SLA),如系统可用性、故障响应与解决时间、服务请求处理时效等。建立基于关键绩效指标(KPI)的考核机制,持续评估并改进运维质量与效率。
二、信息系统运行与维护的核心实践
制度需要通过具体的运维活动来落实。高效的运行与维护实践主要体现在:
- 主动式监控与预防性维护: 利用监控工具对网络、服务器、数据库、应用性能进行7x24小时实时监控,通过趋势分析预测潜在问题,在故障发生前进行干预(如清理日志、扩容资源、更新补丁),变“被动救火”为“主动防火”。
- 流程化的事件与问题管理: 建立统一的服务台作为单一联系点,对所有事件进行记录、分类、分派、跟踪与闭环。对重复发生或重大的事件,启动问题管理流程,深入分析根本原因,制定永久解决方案,防止复发。
- 标准化的变更管理: 任何对生产环境的变更,无论大小,都应遵循申请、审批、测试、实施、验证、回顾的标准流程。这能最大程度减少因变更引发的系统中断或性能下降风险。
- 自动化运维: 对于重复性、规律性的运维任务(如批量部署、配置检查、备份执行、报告生成),积极采用脚本或自动化运维平台(如Ansible, Puppet)实现自动化,提升效率,减少人为失误。
- 知识积累与共享: 建立运维知识库,将常见问题的解决方案、操作手册、应急预案、最佳实践文档化、系统化。这能加速新员工成长,提升团队整体故障解决能力。
三、信息系统运行维护服务的模式与发展
随着技术复杂度的提升和业务对IT依赖的加深,运维服务模式也在不断演进:
- 传统自建团队模式: 企业组建内部运维团队,全面负责自有系统的运维。优点是控制力强,响应直接;缺点是对人员技能、成本投入要求高,难以应对技术快速迭代。
- 外包服务模式: 将全部或部分运维工作(如基础设施、桌面支持、特定应用)外包给专业服务商。可以借助外部专家的力量,降低成本,使企业更聚焦核心业务。关键在于明确SLA,建立有效的沟通与监管机制。
- 云化与托管服务模式: 随着云计算普及,大量系统部署在公有云或采用SaaS模式。此时,运维职责在用户与云服务商之间共享(责任共担模型)。用户侧更侧重于应用层、数据层和访问安全的运维,而基础设施的运维则由云服务商保障。
- DevOps与AIOps的融合: 敏捷开发与运维的深度融合(DevOps)强调自动化、协作与快速反馈。智能运维(AIOps)利用大数据和人工智能技术,实现异常检测、根因分析、智能告警乃至自愈的预测性维护,是运维服务向智能化发展的必然趋势。
###
信息系统的运行维护已从单纯的技术支持角色,转变为驱动业务连续性与创新的战略职能。构建坚实的制度基础,执行高效的运维实践,并选择或融合适合自身发展的服务模式,是企业确保信息系统成为可靠业务引擎的必由之路。持续优化运行维护体系,拥抱自动化与智能化技术,方能在数字化浪潮中行稳致远。
如若转载,请注明出处:http://www.nrcnmwp.com/product/3.html
更新时间:2026-05-04 07:46:00