构建健壮的Kubernetes微服务监控体系 信息系统运行维护服务的关键支柱
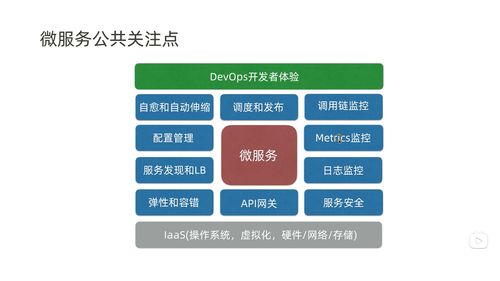
随着企业数字化转型的深入,微服务架构与Kubernetes容器编排平台的结合已成为构建现代化、敏捷信息系统的标准范式。微服务的分布式、动态特性也为信息系统的运行维护带来了前所未有的复杂性。一个全面、深度、自动化的Kubernetes微服务监控体系,不再是可选项,而是保障业务连续性、提升运维效率与服务质量的生命线。
一、 Kubernetes微服务监控的核心挑战与目标
在Kubernetes环境中,微服务监控面临独特挑战:
- 动态性与瞬时性:Pod的频繁创建、销毁与迁移,使得传统的基于静态IP的监控方式失效。
- 多层抽象与依赖:需要穿透Namespace、Deployment、Service、Pod、Container等多层抽象,理解服务间的拓扑与依赖关系。
- 海量维度数据:从基础设施(节点资源)、容器运行时、应用到业务逻辑,产生海量多维度指标、日志与追踪数据。
- 快速故障定位:一个业务请求可能穿越数十个服务,故障根因定位如同“大海捞针”。
因此,监控体系的目标是达成可观测性,即通过指标(Metrics)、日志(Logs)和链路追踪(Traces)三大支柱,实现从外部表现到内部状态的深度洞察,支撑 proactive(主动预防)而非 reactive(被动响应)的运维模式。
二、 分层监控体系架构
一个完整的监控体系应覆盖以下层次:
1. 基础设施层监控
- 监控对象:Kubernetes Node(节点)的CPU、内存、磁盘I/O、网络带宽与状态。
- 关键指标:节点就绪状态、资源请求/限制使用率、磁盘压力。
- 常用工具:Prometheus Node Exporter、Datadog Agent、Zabbix等。
2. Kubernetes核心组件层监控
- 监控对象:API Server、etcd、Scheduler、Controller Manager、kubelet、CoreDNS等控制平面与核心组件。
- 关键指标:API请求延迟与错误率、etcd写入延迟、领导选举状态、组件健康状态。
- 实现方式:利用各组件内置的Metrics端点,由Prometheus抓取。
3. 工作负载与容器层监控
- 监控对象:Deployment、StatefulSet、DaemonSet、Pod、Container。
- 关键指标:Pod状态(Running/Pending/Failed)、容器资源使用率(CPU、内存)、重启次数、就绪与存活探针状态。
- 核心能力:利用Kubernetes的标签(Labels)体系进行灵活分组与聚合查询。
4. 应用性能监控(APM)
- 监控对象:微服务应用内部状态,如JVM(Java)、Go Runtime、HTTP请求等。
- 关键指标:应用接口的请求量(QPS)、响应时间(RT)、错误率(Error Rate)、关键业务指标(如订单创建数)。
- 技术实现:在应用代码中集成SDK(如OpenTelemetry、SkyWalking Agent),或通过Service Mesh(如Istio)的Sidecar代理无侵入采集。
5. 日志集中管理与分析
- 核心需求:聚合所有容器标准输出与应用日志,提供集中存储、检索与分析。
- 技术栈:采用EFK(Elasticsearch, Fluentd/Fluent Bit, Kibana)或Loki(Grafana Loki)栈。Fluent Bit作为轻量级日志收集器常以DaemonSet形式部署在每个节点。
6. 分布式链路追踪
- 核心价值:还原一个端到端请求在微服务间调用的完整路径,用于性能瓶颈分析与故障根因定位。
- 实现标准:遵循OpenTracing/OpenTelemetry标准,使用Jaeger或Zipkin作为后端存储与UI。
三、 监控技术栈选型与实践组合
当前,云原生可观测性栈已成为事实标准:
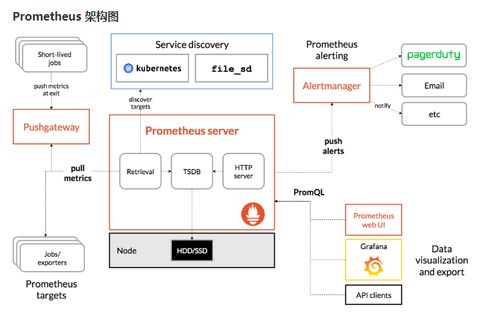
- 指标收集与告警:Prometheus(时序数据库与拉模型) + Alertmanager(告警管理)。
- 可视化与仪表盘:Grafana,支持丰富的数据源(Prometheus, Loki, Elasticsearch等)和强大的图表功能。
- 日志管理:Loki(索引日志内容,与Prometheus/Grafana生态集成紧密)或 ELK/EFK 栈。
- 链路追踪:Jaeger 或 Zipkin。
- 一体化商业方案:Datadog、New Relic、Dynatrace等,提供开箱即用的全栈监控能力,但成本较高。
部署模式:通常将Prometheus、Alertmanager、Grafana、Loki等监控组件本身也以微服务形式部署在Kubernetes集群内,实现自监控。
四、 融入信息系统运行维护服务流程
监控体系的价值最终体现在运维服务中:
1. 智能告警与事件管理
- 基于PromQL定义精准的告警规则,避免告警风暴(如基于同比/环比阈值)。
- 利用Alertmanager的分组、抑制、静默和路由功能,将告警定向至不同团队(如基础设施、应用开发)。
- 与事件管理平台(如PagerDuty、OpsGenie)或ITSM工具(如ServiceNow)集成,实现告警->事件->工单的闭环。
2. 容量规划与成本优化
- 通过历史资源使用率监控,为Pod配置合理的Request和Limit,提升集群资源利用率。
- 结合HPA(水平Pod自动扩缩容)和VPA(垂直Pod自动扩缩容),实现基于指标的弹性伸缩。
3. 故障自愈与自动化运维
- 结合监控指标与Kubernetes Operator模式,实现部分故障的自动化修复(如Pod异常重启、节点故障迁移)。
- 定义SLO(服务等级目标)并持续监控,驱动系统持续优化。
4. 为开发与业务赋能
- 通过Grafana仪表盘向开发团队提供其服务的黄金指标(延迟、流量、错误、饱和度),推动DevOps文化。
- 将业务指标(如交易成功率、用户活跃度)纳入监控,实现技术对业务的直接支撑。
五、
构建Kubernetes微服务监控体系是一项系统性工程,它不仅仅是工具栈的堆砌,更是组织流程、技术实践与文化变革的结合。一个成熟的监控体系能够将信息系统的运行状态从“黑盒”变为“白盒”,使运维服务从被动救火转向主动洞察与价值创造,最终成为保障业务敏捷、稳定与高效增长的坚实基石。运维团队需持续迭代监控策略,使其与微服务架构和业务需求共同演进,方能真正驾驭云原生时代的运维复杂性。
如若转载,请注明出处:http://www.nrcnmwp.com/product/19.html
更新时间:2026-04-16 03:53:58