服务监控系统Prometheus简介与快速入门指南
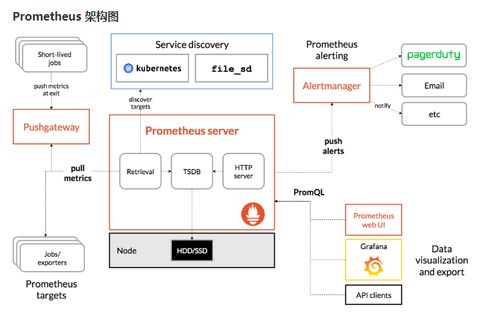
在当今高度数字化的时代,信息系统的稳定、高效运行已成为企业业务连续性的基石。有效的运行维护服务不仅需要快速响应故障,更需要具备前瞻性的监控能力,以预防问题的发生。在这一背景下,服务监控系统的重要性日益凸显。本文将聚焦于当下最流行的开源监控解决方案之一——Prometheus,对其进行简要介绍,并提供一份针对信息系统运行维护服务的快速入门指南。
一、Prometheus简介:现代监控系统的标杆
Prometheus是一款于2012年在SoundCloud公司诞生的开源系统监控和告警工具包。它于2016年正式加入云原生计算基金会(CNCF),并成为继Kubernetes之后第二个从该基金会毕业的项目,这标志着其在稳定性、成熟度和社区活跃度方面达到了行业顶级标准。
其核心设计理念围绕以下几个关键点:
- 多维数据模型:Prometheus通过指标名称和一组键值对(标签)来标识时间序列数据。这种强大的数据模型使得数据的筛选、聚合和查询变得异常灵活和高效。
- 灵活的查询语言(PromQL):这是Prometheus的“灵魂”。用户可以利用PromQL对收集到的多维时间序列数据进行实时查询和聚合,从而生成图表、表格或触发告警。
- 拉取(Pull)模型:与传统的代理推送(Push)模型不同,Prometheus服务器主动从配置好的目标(如应用、服务器)上通过HTTP协议“拉取”指标数据。这种模型简化了被监控端的配置,并让监控服务器更容易了解自身的状态。
- 自治与去中心化:每个Prometheus服务器都是独立的,不依赖于分布式存储。这使得部署和维护非常简单,只需依赖本地磁盘即可。
- 强大的集成生态:Prometheus拥有丰富的客户端库(支持Go, Java, Python等十余种语言),可以轻松地将应用指标暴露出来。它支持众多 exporter(导出器),用于监控第三方系统,如Linux主机、MySQL数据库、Nginx服务器等。
二、快速入门:为您的运维服务部署Prometheus
对于信息系统运行维护团队,快速搭建一个可用的监控环境是首要任务。以下是部署和配置Prometheus的四个核心步骤:
第一步:下载与安装
访问Prometheus官网(prometheus.io)的下载页面,根据您的服务器操作系统(如Linux)选择对应的预编译二进制包。解压后,您会得到几个核心文件:prometheus(主程序)、prometheus.yml(主配置文件)以及promtool等工具。
第二步:基础配置
编辑 prometheus.yml 配置文件。一个最简单的配置示例如下:
`yaml
global:
scrape_interval: 15s # 每15秒抓取一次数据
evaluation_interval: 15s # 每15秒评估一次告警规则
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093 # 告警管理器地址,初期可暂不配置
rulefiles:
# - "firstrules.yml" # 告警规则文件,初期可暂不配置
scrape_configs:
- jobname: 'prometheus' # 监控Prometheus自身
staticconfigs:
- targets: ['localhost:9090']
- jobname: 'nodeexporter' # 监控Linux主机
static_configs:
- targets: ['yourserverip:9100'] # 需安装并运行node_exporter`
第三步:启动与验证
在终端中运行 ./prometheus --config.file=prometheus.yml 启动服务。默认情况下,Prometheus会在本地的9090端口启动。打开浏览器,访问 http://your<em>server</em>ip:9090,您将看到Prometheus的Web UI。
第四步:初步探索与监控
- 监控自身:在Web UI的“Graph”页面,输入
up并执行查询。up指标可以告诉您配置的抓取目标(如Prometheus自身)是否健康(值为1表示正常)。 - 添加第一个监控目标:为了监控服务器的CPU、内存、磁盘等基础资源,您需要在目标服务器上部署并运行
node<em>exporter(同样从官网下载)。启动后,它会暴露主机指标在9100端口。确保修改上述配置文件中的your</em>server_ip并重启Prometheus,即可看到新目标。 - 使用PromQL:尝试一些简单的查询,例如:
node<em>memory</em>MemFree_bytes:查看系统空闲内存。
rate(node<em>cpu</em>seconds_total{mode="system"}[1m]):计算过去1分钟内系统态CPU使用率的变化速率。
三、融入运维服务体系:从监控到洞察
快速部署只是第一步。要将Prometheus真正融入信息系统运行维护服务,建议遵循以下路径:
- 分层监控:
- 基础设施层:使用
node<em>exporter、snmp</em>exporter等监控服务器、网络设备、存储等硬件资源。
- 中间件与服务层:使用对应的 exporter(如
mysqld_exporter,nginx-vts-exporter)监控数据库、Web服务器、消息队列等。
- 应用层:在业务代码中集成Prometheus客户端库,暴露自定义的业务指标(如每秒请求数、订单处理时长、错误计数)。
- 可视化与告警:
- 将Prometheus与Grafana结合,可以创建功能强大、美观的业务仪表盘,实现数据的可视化展示。
- 配置
Alertmanager与告警规则(rule_files),实现基于指标的主动告警,通过邮件、钉钉、企业微信等渠道通知运维人员。
- 形成运维闭环:
- 故障发现:通过监控面板和告警第一时间感知系统异常。
- 根因定位:利用Prometheus的多维查询能力,通过逐层下钻(从业务层到基础设施层)快速定位问题根源。
- 性能优化与容量规划:基于长期收集的历史数据,分析性能趋势,为系统扩容和优化提供数据支撑。
###
Prometheus以其简洁的架构、强大的查询能力和活跃的生态,为现代信息系统的运行维护提供了一个坚实、灵活的监控基础。对于运维团队而言,掌握Prometheus不仅意味着多了一个高效的故障排查工具,更意味着能够建立起一套以数据驱动的、主动预防式的运维服务体系。从今天的快速入门开始,逐步构建起覆盖全栈的监控能力,您的运维工作将迈入一个全新的、可观测的时代。
如若转载,请注明出处:http://www.nrcnmwp.com/product/20.html
更新时间:2026-04-16 08:10:05